
Table of Contents
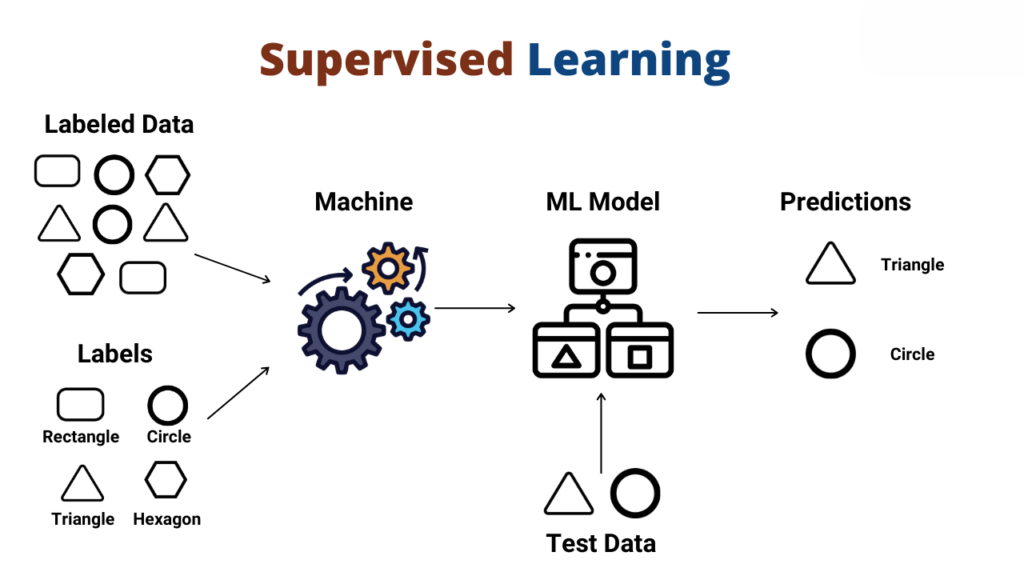
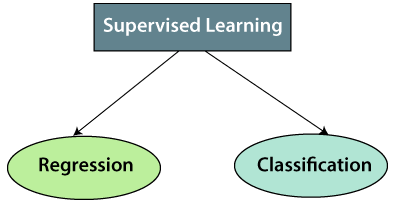
- Classification: In classification tasks, the output variable is categorical, meaning it belongs to a finite set of classes or categories. The goal is to assign a class label to each input data point. Examples include email spam detection, sentiment analysis, and image classification.
- Regression: In regression tasks, the output variable is continuous, meaning it can take on any numerical value within a range. The goal is to predict a continuous value or quantity based on the input features. Examples include predicting house prices, estimating sales revenue, and forecasting stock prices.
Supervised learning is widely used in various applications across industries, including healthcare, finance, marketing, and natural language processing, among others. It is a powerful approach for solving predictive modeling problems where labeled data is available for training.