
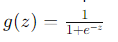
- Here, z is the linear combination of the input features and their corresponding coefficients
- Linear Combination
- Similar to linear regression, logistic regression calculates a linear combination of the input features and their corresponding coefficients:
z=β0+β1x1+β2x2+…+βnxn
- The linear combination z is then passed through the sigmoid function to obtain the predicted probability
- Decision Boundary
- Logistic regression predicts the probability that an observation belongs to a particular class (e.g., 0 or 1). By default, if the predicted probability is greater than or equal to 0.5, the observation is classified as belonging to class 1; otherwise, it's classified as belonging to class 0.
- The decision boundary is the threshold value (usually 0.5) that separates the two classes.
- Training
- The logistic regression model is trained using maximum likelihood estimation. The goal is to find the coefficients β0,β1,…,βn that maximize the likelihood of observing the actual classes given the input features
- This is typically done using optimization algorithms such as gradient descent or Newton's method
- Evaluation
- Once trained, the logistic regression model can be used to make predictions on new data points. Predictions are obtained by applying the trained model to the input features and converting the output probabilities into class labels using the decision boundary.
- Regularization
Logistic regression can be regularized to prevent overfitting by adding penalty terms to the cost function. The two most common types of regularization are L1 regularization (Lasso) and L2 regularization (Ridge)
- Interpretation
The coefficients β0,β1,…,βn of logistic regression provide insights into the relationship between the input features and the log-odds of the outcome. Positive coefficients indicate that an increase in the corresponding feature increases the probability of belonging to class 1, while negative coefficients indicate the opposite.
Logistic regression is widely used in various fields such as healthcare (predicting disease risk), marketing (customer churn prediction), and finance (credit risk assessment). It's a simple yet powerful algorithm for binary classification tasks.