CS301: Computer Architecture Exam Quiz Answers
Question 1: Time-sharing systems typically consist of which of the following? Select one:
- More than one program in memory
- More than one memory in the system
- More than one processor in the system
- More than two processors in the system
Question 2: When an instruction is read from program memory, where does the control unit route it to? Select one:
- The ALU
- Back to memory
- The program counters
- The instruction registers
Question 3: Where does a computer add and compare data? Select one:
- CPU chip
- Floppy disk
- Hard disk
- Memory chip
Question 4: For a future exascale computer, which of the following will the low-power processor most likely be modeled after? Select one:
- Apple’s iMacs
- IBM’s Watson
- Mobile devices
- Supercomputers
Question 5: Which of the following registers is used to keep track of the address of the memory location where the next instruction is located? Select one:
- Instruction Register
- Memory Data Register
- Memory Address Register
- Program Counter Register
Question 6: In this diagram, what would bits 4 and 5 in the instruction register need to be to route the data to the ALU?
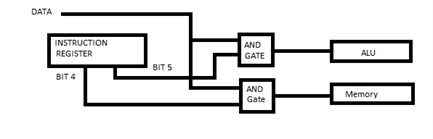
Select one:
- 00
- 01
- 10
- 11
Question 7: What is the 2’s complement representation of -62? Select one:
- 00111110
- 11000001
- 11000010
- 11100010
Question 8: What is the binary representation of the integer 75? Select one:
- 01001010
- 01001011
- 01101010
- 11001111
Question 9: Consider the C program statement a = b + 10; and that the ADDI assembly language statement has the following format: 001000 | 5 bits rs | 5 bits rt | 16 bits. Suppose the variable b goes in register 3 and a in register 5. What binary code is loaded into program memory for this C program statement? Select one:
- 00010000011001010000000000000101
- 00010000011001010000000000001010
- 00100000011001010000000000000101
- 00100000011001010000000000001010
Question 10: Memory access in MIPS architecture is carried out using what instructions? Select one:
- ST and LD
- JR and BEQ
- ADD and SUB
- PUSH and POP
Question 11: Which of the following instructions belongs to an I-Format instruction type in a MIPS processor? Select one:
- add
- jr
- ld
- or
Question 12: What is the minimum sum of products expression, given this KMAP?
| ab | |||||
| 00 | 01 | 11 | 10 | ||
| cd | 00 | X | 1 | 1 | |
| 01 | X | ||||
| 11 | 1 | ||||
| 10 | 1 | 1 | X | ||
Select one:
- b’d’ + a’b
- ab’ + a’d’
- d’ + ab’
- ac + a’bd’
Question 13: Which of the following is true for a 4-bit ripple carry adder? Select one:
- There are three stages
- There is a clock line going to each full adder
- The adder is slower than a carry looks ahead adder
- Extra gates are needed besides the full adder gates
Question 14: For this state machine, if we encode states S0 and S1 using a single bit, where 0 represents S0 and 1 represents S1, and we represent the inputs by a and b, then which of the following logic equations will be the state machine’s output?
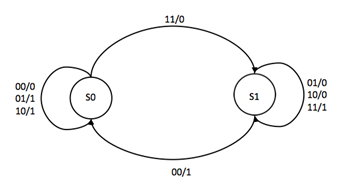
Select one:
- [ab + a’b’] S’ + [a’b + ab’] S
- [ab + a’b] S’ + [a’b’ + ab’] S
- [a’b + a’b’] S’ + [ab + ab’] S
- [ab’ + a’b] S’ + [ a’b’ + ab] S
Question 15: Which of the following snippets of pseudocode can you use to find the quotient of a division, using a 4-bit hardware adder/subtractor? Select one:
- Loop a times {
b = b + b
} answer = b
- c = 0
Loop a times {
c = c + b
} answer = b
- Assume b > a
Loop n times {
b = b – a
if (b = 0) answer = n
if (b < 0) answer = n – 1
}
Assume b > a
- Loop n times {
b = b – a
if (b = 0) answer = 0
if (b < 0) answer = b + a
}
Question 16: If you use two half adders to build a full adder, which gates would you use? Select one:
- 1 XOR, 1 AND, 2 OR
- 1 XOR, 2 AND, 1 OR
- 2 XOR, 2 AND, 1 OR
- 2 XOR, 1 AND, 2 OR
Question 17: Which of the following can be the value of the program counter after fetching of an instruction in a MIPS processor? Select one:
- PC
- PC+4
- 2*PC
- 2*PC-1
Question 18: A data hazard is a situation where which of the following is true? Select one:
- One stage must wait for data from another stage in the pipeline
- The pipeline is not able to provide any speedup to execution time
- The next instruction is determined based on the results of the currently-executing instruction
- Hardware is unable to support the combination of instructions that should execute in the same clock cycle
Question 19: A structural hazard is a situation where which of the following is true? Select one:
- One stage must wait for data from another stage in the pipeline
- The pipeline is not able to provide any speedup to execution time
- The next instruction is determined based on the results of the currently-executing instruction
- Hardware is unable to support the combination of instructions that should execute in the same clock cycle
Question 20: 5f.1. Which of the following factors is most likely to limit the performance of a processor? Select one:
- Control hazard
- Static parallelism
- Dynamic parallelism
- Speculative execution
Question 21: One major advantage of direct mapping of a cache is that the mapping itself is very simple. What is the main disadvantage of this organization? Select one:
- It is more expensive than other types of cache organizations
- Its access time is greater than that of other cache organizations
- Its cache hit ratio is typically worse than with other organizations
- It does not allow simultaneous access to the intended data and its tag
Question 22: Assume that there is a direct-mapped cache of size 8 words. How many misses will there be, given the sequence of block addresses 0, 1, 0, 8, 1? Select one:
- 0
- 1
- 3
- 5
Question 23: When a page fault occurs, where does the missing page come from? Select one:
- A disk
- A cache
- The register files
- The main memory
Question 24: Which of the following holds the mapping of a virtual address to a physical address? Select one:
- Disk
- Cache
- Page table
- Virtual Memory
Question 25: What do we call interrupts that are initiated by an instruction? Select one:
- Asynchronous
- External
- Internal
- Synchronous
Question 26: Which of the following statements about a RAID 1 disk system is true? Select one:
- There are no redundant check disks
- The number of redundant check disks is equal to the number of data disks
- The number of redundant check disks is less than the number of data disks
- The number of redundant check disks is more than the number of data disks
Question 27: Which parallel programming API is most suitable for programming a Shared Memory Multiprocessor? Select one:
- C/C++
- MPI
- OpenMP
- Python
Question 28: According to Amdahl’s law, which of the following statements is true? Select one:
- There is no improvement in performance as the number of processors increase
- There is a diminishing improvement in performance as the number of processors increase
- There is an increasing improvement in performance as the number of processors increase
- There can be no more than a 5 times improvement in performance as the number of processors increase
Question 29: If we can speed up the parallel portion of a program by a factor of 3, and the parallel portion is approximately 50% of the total program, then how much more quickly will the program run? Select one:
- 1.5 times faster
- 1.67 times faster
- 2 times faster
- 3 times faster
Question 30: Which of the following do Shared Memory Multiprocessors (SMP) offer the programmer? Select one:
- Uniform memory access
- A single physical address space
- One physical address space per processor
- Multiple memories shared by multiprocessors
Question 31: Message-passing-based programming is more suitable for which of the following? Select one:
- SIMD Machines
- MIMD machines
- Shared Memory Multiprocessors
- Distributed Shared Memory Multiprocessors
Question 32: What is one of the reasons why It may not be possible to extract more instruction level parallelism from written code, thus making the switch to parallel processing a useful alternative? Select one:
- Most programs are too long
- The use of cache memory for data
- The use of cache memory for instructions
- Because of compiler limitations
Question 33: Which of the following descriptions for a Graphic Processing Unit (GPU) is true? Select one:
- It is a processor that has multiple levels of cache
- It is a processor that is efficient for all types of computing
- It is a special purpose processor only useful for graphics processing
- It is a processor used in all types of applications that involve data parallelism
Question 34: What is the binary representation of 52.75? Select one:
- 00101001.11
- 00110100.11
- 00110110.10
- 00111011.01
Question 35: In immediate addressing, where is the operand placed? Select one:
- In the stack
- In the memory
- In the CPU register
- After OP code in the instruction
Question 36: Which of the following expressions is equivalent to this logic gate structure? Select one:
- F = x + y’z
- F = xy’ + yz + xz
- F = xy + y’z + xz
- F = xy’z + xy’z’ + x’yz + x’yz
Question 37: Which two gates are used to build a half adder? Select one:
- AND, OR
- OR, NOT
- XOR, OR
- XOR, AND
Question 38: What circuitry, in addition to an adder, do you need to perform subtraction in hardware? Select one:
- AND gates and MUXes
- NOT gates and MUXes
- OR gates and DEMUXes
- XNOR gates and DECODERs
Question 39: If you build a full adder from two half adders, how many gates do you need? Select one:
- 2
- 3
- 4
- 5
Question 40: The MIPS instruction add $s0, $t0, $t1 followed by sub $t2, $s0, $t3 is likely to result in which of the following? Select one:
- A data hazards
- A memory faults
- A control hazards
- A structural hazard
Question 41: The MIPS instruction add $s0, $t0, $t1 followed by sub $t2, $s0, $t3 can be executed more efficiently through the use of which of the following? Select one:
- Value prediction
- Branch prediction
- Memory unit forwarding
- Execution unit forwarding
Question 42: Which of the following is a hardware method of increasing processor performance? Select one:
- Carry lookahead
- Branch prediction
- Register renaming
- Out of order execution
Question 43: Which of the following types of cache technology is most closely associated with superscalar processing? Select one:
- “Hit under miss”
- High associativity
- Multiported caches
- Segregated caches
Question 44: Which of the following is the correct order of elements in a memory hierarchy, from fastest to slowest times of access? Select one:
- Cache, Main Memory, Disk, Register
- Cache, Main Memory, Register, Disk
- Cache, Register, Main Memory, Disk
- Register, Cache, Main Memory, Disk
Question 45: Which of the following types of memory is flash storage? Select one:
- Cache memory
- Volatile memory
- Non-cache memory
- Non-volatile memory
Question 46: What is the maximum possible speedup achievable for a program with 50% sequential code? Select one:
- 2
- 4
- 16
- 32
Question 47: Why is synchronization needed in parallel programs? Select one:
- Threads may use local variables
- Threads may use private variables
- Threads may use shared variables
- Using a semaphore is not effective
Question 48: Which of the following is a key reason for the switch to parallel processing? Select one:
- Increase in speed of processor chips
- Increase in power density of the chip
- Increase in video and graphics processing
- Increase in cost of semiconductor manufacturing
Question 49: Which of the following is the best example of an application of cloud computing? Select one:
- Load balancing
- Grid computing
- Web search engine
- Scientific computing
Question 50: Which of the following is an example of a special purpose application of parallel computing? Select one:
- A Monte Carlo integration
- Any highly sequential program
- A C++ program with lots of for loops
- A program with fine-grained parallelism
Question 51: Moore’s Law explains that which of the following will double roughly every 18-24 months? Select one:
- Clock frequency
- Transistors on a chip
- Processors on a chip
- Chip power consumption
Question 52: What is the branch logic that provides decision-making capabilities in the control unit known as? Select one:
- Controlled transfer
- Conditional transfer
- Uncontrolled transfer
- Unconditional transfer
Question 53: What is the hexadecimal representation of the integer 125? Select one:
- 6E
- 7D
- 8A
- B5
Question 54: Which of these numbers is in normalized form? Select one:
- 1.0× 10-9
- 10.0 × 10-9
- 100.00 × 10-9
- 1000.00 × 10-9
Question 55: What is a computer program that translates an entire program into machine language at one time called? Select one:
- Commander
- Compiler
- Interpreter
- Simulator
Question 56: Which of the following instructions belongs to a R-Format instruction type in a MIPS processor? Select one:
- add
- beq
- jr
- ld
Question 57: Which of the following most accurately describes the execution of a R-type instruction? Select one:
- Data memory and Register File take part
- Instruction memory and data memory take part
- Instruction memory, ALU, and register take part
- Instruction memory, Register File, ALU, and data memory take part
Question 58: Which of the following is the fastest member of the memory hierarchy? Select one:
- Cache
- Register
- Hard disk
- Main memory
Question 59: You want to calculate the performance (bandwidth) of the following busses. You have a synchronous bus with the following specifications: 60Mhz frequency, 16.7ns clock cycle (CK), sending address/data takes 1 CK each, and a 100ns memory access time. You also have an asynchronous with the following specifications: each handshake takes 30ns, with the same 100ns memory access time. Assume 4 bytes of data to be transferred across the bus. Which bus has better bandwidth? Select one:
- The synchronous bus is better: 20.1 vs. 15.3 MB/s
- The synchronous bus is better: 30 vs. 18.2 MB/s
- The asynchronous bus is better: 13.3 vs. 11.1 MB/s
- The asynchronous bus is better: 20.1 vs. 15.3 MB/s
Question 60: Which of the following statements about a RAID 4 system is true? Select one:
- RAID 4 does not use parity
- RAID 4 uses bit-interleaved parity
- RAID 4 uses block-interleaved parity
- RAID 4 uses distributed block-interleaved parity
Question 61: Which of the following statements about multithreading is true? Select one:
- Multiple threads are used in multiple cores
- Multiple threads are used in multiple processors
- Multiple threads share a single processor, but do not overlap
- Multiple threads share a single processor in an overlapping fashion
Question 62: According to Amdahl’s Law, as the number of processors increases, how does the execution time behave? Select one:
- It stays the same
- It decreases to zero
- It approaches the execution time of the sequential part of the code
- It approaches the execution time of the non-sequential part of the code
Question 63: For this state machine, what are the number of states, the number of inputs, and the number of outputs?
Select one:
- 1 state, 2 inputs, 2 outputs
- 2 states, 2 inputs, 1 output
- 3 states, 1 input, 2 outputs
- 3 states, 2 inputs, 1 output
Question 64: What does the phrase “dedicated computer” mean? Select one:
- A computer that is used by one person only
- A computer that runs only one kind of software
- A computer that is assigned to one and only one task
- A computer that is meant for application software only
Question 65: Which of the following semiconductor families was developed first? Select one:
- DTL
- PMOS
- RTL
- TTL
Question 66: What is the minimum sum of products expression, given this KMAP?
| ab | |||||
| 00 | 01 | 11 | 10 | ||
| cd | 00 | 1 | X | ||
| 01 | 1 | 1 | X | 1 | |
| 11 | |||||
| 10 | 1 | 1 | |||
Select one:
- cd’ + bd
- c’ + ab’
- c’d + b’d’
- ad + b’d’
Question 67: What is the minimum sum of products expression, given this truth table?
| a | b | c | z |
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
Select one:
- a + b
- b + c
- ac + b
- a’b + c
Question 68: Which of the following snippets of pseudocode can you use to find the remainder of a division, using a 4-bit hardware adder/subtractor? Select one:
- Loop a times {
b = b + b
} answer = b
- c = 0
Loop a times {
c = c + b
} answer = b
- Assume b > a
Loop n times {
b = b – a
if (b = 0) answer = n
if (b < 0) answer = n – 1
}
- Assume b > a
Loop n times {
b = b – a
if (b = 0) answer = 0
if (b < 0) answer = b + a
}
Question 69: What is the starting point for the execution of an instruction in a MIPS processor? Select one:
- The decoding of the instruction
- The reading of the program counter value
- The execution of operation using the ALU
- The fetching of the instruction from the instruction memory
Question 70: The CPU deals with each instruction in a cycle. The sequence of instructions to carry out one machine instruction is called the instruction or machine cycle. The first action is to fetch the instruction from memory and then the program counter is updated (reset). What are the other three phases of the machine cycle in the correct order? Select one:
- Decode the instruction; execute the instruction; transfer the data
- Decode the instruction; transfer the data; execute the instruction
- Execute the instruction; decode the instruction; transfer the data
- Transfer the data; execute the instruction; decode the instruction
Question 71: A control hazard is a situation where which of the following is true? Select one:
- One stage must wait for data from another stage in the pipeline
- The pipeline is not able to provide any speedup to execution time
- The next instruction is determined based on the results of the currently-executing instruction
- Hardware is unable to support the combination of instructions that should execute in the same clock cycle
Question 72: Which of the following software methods can be used to increase processor performance? Select one:
- Caching
- Pipelining
- Carry lookahead
- Branch prediction
Question 73: 5f.2. Which of the following factors is most likely to limit the performance of a processor? Select one:
- Pipelining
- Data hazard
- Concurrency
- Instruction level parallelism
Question 74: Which of the following does the valid bit in the cache indicate? Select one:
- The cache block number
- Whether there is a write-through or not
- Whether the requested word is in the cache or not
- Whether the cache entry contains a valid address or not
Question 75: When a cache miss occurs, where does the missing block of data come from? Select one:
- A disk
- A cache
- The register files
- The main memory
Question 76: The Translation-Lookaside Buffer (TLB) is related to the Page Table (PT) in the way that the ____ is related to the ____. Select one:
- Tape drive; PT
- PT; victim cache
- Dcache; Write buffer
- Dcache; Main memory
Question 77: You want to calculate the performance (bandwidth) of the following busses. You have a synchronous bus with the following specifications: 50Mhz frequency, 20ns clock cycle (CK), sending address/data takes 1 CK each, and a 120ns memory access time. You also have an asynchronous bus with the following specifications: each handshake takes 25ns, with the same 120ns memory access time. Assume 4 bytes of data to be transferred across the bus. Which bus has better bandwidth? Select one:
- The synchronous bus is better: 25 vs. 18.2 MB/s
- The synchronous bus is better: 30 vs. 25.2 MB/s
- The asynchronous bus is better: 13.3 vs. 11.1 MB/s
- The asynchronous bus is better: 30 vs. 25.2 MB/s
Question 78: You have a 32-bit synchronous bus with f = 200Mhz, 5ns clock cycle (CK), sending data/address takes 1 CK each, 2 CKs between bus operation, a memory access time of 200ns, bus transfer and reading next data overlap, and a block size of 8 words. What is the bandwidth for 256 4-byte words to be transferred over the bus? Select one:
- 100.2 MB/s
- 130.6 MB/s
- 150.8 MB/s
- 170.0 Mb/s
Question 79: What do we call interrupts that are initiated by an I/O drive? Select one:
- Asynchronous
- External
- Internal
- Synchronous
Question 80: Which of the following statements about a RAID 0 disk system is true? Select one:
- There are no redundant check disks
- The number of redundant check disks is equal to the number of data disks
- The number of redundant check disks is less than the number of data disks
- The number of redundant check disks is more than the number of data disks
Question 81: What is the maximum possible speedup achievable for a program with 75% sequential code? Select one:
- 1.3333
- 2
- 2.6666
- 8
Question 82: Gustafson’s law modifies Amdahl’s law with regard to which of the following factors? Select one:
- Weak scaling
- Timing issues
- Strong scaling
- Communication overhead
Question 83: Which of the following outlines the correct order that semiconductor families were developed, from earliest to latest? Select one:
- DTL RTL CMOS TTL
- DTL RTL TTL CMOS
- RTL DTL TTL CMOS
- RTL TTL DTL CMOS
Question 84: If you want to design a finite state machine that has n states and want to use one-shot encoding for the states, what is the number of bits required to encode the states? Select one:
- 1
- n
- log n
- 2n
Question 85: What is the final step in the fetch cycle of a MIPS processor? Select one:
- Decoding the instruction
- Reading the program counter value
- Executing the operation using the ALU
- Fetching the instruction from the instruction memory
Question 86: Which of the following updates the data values in the register file in a MIPS processor? Select one:
- The program counters
- The output of the ALU
- Data from data memory
- Decoding instructions from instruction memory
Question 87: Which of the following is the maximum possible speedup in a pipelined machine? Select one:
- The number of pipe stages
- 5 times that of a non-pipelined machine
- The ratio of the fetch cycle period to the clock period
- The ratio of time between instructions and clock cycle time
Question 88: The MIPS instruction lw $s0, 40($t1) followed by sub $t2, $s0, $t3 can be executed more efficiently through the use of which of the following? Select one:
- Value prediction
- Branch prediction
- Memory unit forwarding
- Execution unit forwarding
Question 89: You have a 32-bit synchronous bus with f = 200Mhz, 5ns clock cycle (CK), sending data/address takes 1 CK each, 2 CKs between bus operation, a memory access time of 200ns, bus transfer and reading next data overlap, and a block size of 32 words. What is the bandwidth for 256 4-byte words to be transferred over the bus? Select one:
- 131.0 MB/s
- 229.4 MB/s
- 327.9 MB/s
- 350.1 MB/s
Question 90: Which of the following is an example of a special purpose application of parallel computing? Select one:
- Ranking a linked list
- A matrix multiplication
- Any highly sequential program
- A program with fine-grained parallelism
Introduction to Computer Architecture
Computer architecture is a fascinating and crucial field in computer science and engineering that deals with the design and organization of computer systems. It encompasses various aspects, including the following:
- Instruction Set Architecture (ISA): This defines the set of instructions that a computer’s CPU can execute. It includes the CPU’s registers, data types, instructions, and addressing modes. Examples include x86, ARM, and MIPS.
- Microarchitecture: This refers to the implementation of the ISA. It involves the design of the CPU’s internal structure, including the arithmetic logic unit (ALU), registers, cache, and pipelines. It’s about how the ISA is realized in hardware.
- Memory Hierarchy: This involves the design of various types of memory used in a computer system, such as registers, cache (L1, L2, L3), RAM (main memory), and storage (hard drives, SSDs). The goal is to balance speed, cost, and capacity.
- Processor Design: This includes various techniques to improve CPU performance, such as pipelining, superscalar execution, out-of-order execution, and branch prediction. It also involves the design of multi-core processors and the coordination between multiple cores.
- Input/Output Systems: This covers how a computer interacts with external devices like keyboards, mice, printers, and network interfaces. It involves understanding bus architectures, I/O ports, and data transfer protocols.
- System Design: This encompasses the overall organization of a computer system, including the integration of the CPU, memory, and I/O components. It also includes considerations for system performance, reliability, and scalability.
- Parallel and Distributed Computing: This deals with architectures designed to execute multiple processes simultaneously, either within a single machine (multi-core processors) or across a network of machines (clusters, grids, or cloud computing).
- Performance Metrics: Understanding and improving performance involves metrics like clock speed, instructions per cycle (IPC), and throughput. Techniques such as benchmarking and profiling are used to evaluate and optimize system performance.
- Power and Thermal Management: As computers become more powerful, managing power consumption and heat generation becomes crucial. Techniques include dynamic voltage and frequency scaling (DVFS) and advanced cooling solutions.
- Security: Modern computer architecture must consider security at various levels, including secure boot mechanisms, trusted execution environments (TEEs), and protection against side-channel attacks.
Computer architects strive to design systems that balance performance, power efficiency, cost, and other factors to meet the requirements of specific applications and use cases. They often use simulation, modeling, and performance analysis techniques to evaluate design choices and optimize system performance.